Cassandra Demystified
Cassandra is a massive decentralized ,scalable and distributed data store .
Apache Cassandra is an open source distributed database system that is designed for storing and managing large amounts of data across commodity servers. Cassandra can serve as both a real-time operational data store for online transactional applications and a read-intensive database for large-scale business intelligence (BI) systems.
Apache Cassandra is described, in their own words as:
“A highly scalable second-generation distributed database, bringing together Dynamo’s fully distributed design and Bigtable’s ColumnFamily-based data model.”

Cassandra unlike any other distributed datastore follows the basic principles Brewer's CAP theorem as below
Consistency (All Nodes see the same data all the time
Availability (a guarantee that every request receives a response about whether it was successful or failed)
Partition Tolerance (the system continues to operate despite arbitrary message loss or failure of part of the system)
So Why Cassandra ?
Performance Statistics of a normal MySQL/Cassandra with regards to 50 GB data
a)300 ms write
b)350 ms read
Cassandra
a)0.12 ms write
b)15 ms read
RDMS world vs Cassandra
Performance Statistics of a normal MySQL/Cassandra with regards to 50 GB data
a)300 ms write
b)350 ms read
Cassandra
a)0.12 ms write
b)15 ms read
RDMS world vs Cassandra
a)Relational Databases are very slow
b)In RDBMS world Joins affect performance on large scale data
c)In RDBMS world tables are predefined with regards to data type ,constraints etc and queries are modelled based on database tables
Cassandra's Advantages
a)Blazing speed retreival of data
b)There is absolutely no need of predefined relations or joins that need to exist across tables
c)The structure of data can change dynamically across each tuple defined
Insights into Cassandra Architecture and DataModel
A Cassandra instance is a collection of independent nodes that are configured together into a cluster. In a Cassandra cluster, all nodes are peers, meaning there is no master node or centralized management process. A node joins a Cassandra cluster based on certain aspects of its configuration.
Key Aspects of Cassandra DataModel
There are three important aspects of Cassandra DataModel and they are
a)Column,SuperColumn
b)Column Family,SuperColumnFamily
c)Keyspace
Column:
Column is a smallest increment of Data.Its a tuple that contains name,value and timestamp.An example column structure represented using JSON-ish format as below
{
name:eventId,
value:1245,
timestamp:123456789
}
Timestamp is default part of every column that you define in Cassandra.The name and value are internally stored as byte[] by cassandra and can be of any length

SuperColumn
A SuperColumn is a tuple w/ a binary name & a value which is a map containing an unbounded number of Columns – keyed by the Column‘s name. Keeping with the JSON-ish notation we get:
{ // this is a SuperColumn
name: "homeAddress",
// with an infinite list of Columns
value: {
// note the keys is the name of the Column
street: {name: "street", value: "4444 x street", timestamp: 123456789},
city: {name: "city", value: "san jose", timestamp: 123456789},
zip: {name: "zip", value: "95136", timestamp: 123456789},
}
}

Column Vs SuperColumn
Columns and SuperColumns are both a tuples w/ a name & value. The key difference is that a standard Column‘s value is a “string” and in a SuperColumn the value is a Map of Columns. That’s the main difference their values contain different types of data. Another minor difference is that SuperColumn‘s don’t have a timestamp component to them.
ColumnFamily
A column family is a structure used to group both columns and supercolumns.Column family are of two types a)standard b)supercolumnfamily
A column family can be compared to a table in the RDBMS world.It can be imagined as a table with infinite number of rows.In a column family each row contains a key and a map of columns.Keys in the map are names of columns and values are columns themselves.There are few key aspects to column family in Cassandra
a)Rows do not have a predefined list of columns they can contain
b)There is no specific schema enforced at this level
Example of a ColumnFamily
UserProfile={//this is a ColumnFamily
homeAddress: {// this is the key to this Row inside the C
street:"4444 x street",
city:"san jose",
zip: "95136",
timestamp: 123456789,
}
homeAddressVacation: {// this is the key to this Row inside the C
street:"1111 x street",
city:"san fransisco",
zip: "9500",
phone: "(888) 555-1212" ,
timestamp: 123456789,
}
}
As per the example above you can see that the row with key homeAddress has only street,city,zip and timestamp whereas the row with key homeAddressVacation has street,city,zip,phone and timestamp.The rows in Cassandra can have varying number of columns and this is basically the schemaless aspect of Cassandra
SuperColumnFamily
A column family can be super too.When a ColumnFamily is of type Super we have the opposite: each Row contains a map of SuperColumns. The map is keyed with the name of each SuperColumn and the value is the SuperColumn itself
UserProfile={//this is a ColumnFamily
homeAddress: {// this is the key to this Row inside the SuperColumnFamily
// now we have an infinite # of super columns in this row
// the keys inside the row are the names for the SuperColumns
friend1:{street:"4444 x street", city:"san jose", zip: "95136", timestamp: 123456789}
friend2:{street:"111 x street", city:"san fransisco", zip: "95122", timestamp: 123456789}
}
homeAddressVacation: {// this is the key to this Row inside the SuperColumnFamily
// now we have an infinite # of super columns in this row
// the keys inside the row are the names for the SuperColumns
friendA:{street:"1111 x street",city:"san fransisco", zip: "95000",phone: "(888) 555-1212",timestamp: 123456789}
friendB:{street:"2222 x street",city:"san fransisco", zip: "95010",phone: "(888) 555-1212",timestamp: 123456789}
}
}
Summary of Keyspace,Column,ColumnFamily
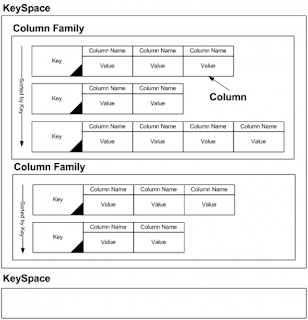
Data Types of Columns in Cassandra
Columns are normally sorted by the column type and the column types in cassandra are
a)BytesType
b)UTF8Type
c)AsciiType
d)LongType
e)LexicalUUIDType
f)TimeUUIDType
How data is written in Cassandra
Every time a Cassandra node receives a request to store data it consistently hashes the data, with md5 when using RandomPartitioner, to get a “token” value. The token range for data is 0 – 2^127.
Every node in a Cassandra cluster, or “ring”, is given an initial token. This initial token defines the end of the range a node is responsible for the same.
Cassandra is not “fixed” in the way that it places data around the ring. It uses two components, Snitches and Strategies, to determine which nodes will receive copies of data. Snitches define proximity of nodes within the ring. Strategies use the information Snitches provide them about node proximity along with an implemented algorithm to collect nodes that will receive writes.

Write Process of Cassandra
All the write operations are written to a commit log and from the commit log the data is populated to the memtable (in memmory table) and then eventually pushed to the underlying SSTable

Read Process of Cassandra
During the read the data is first looked up from in memmory Memtable and if the data is not present in the Memtables the data is read from underlying SStable directly

Insights into Cassandra Architecture and DataModel
A Cassandra instance is a collection of independent nodes that are configured together into a cluster. In a Cassandra cluster, all nodes are peers, meaning there is no master node or centralized management process. A node joins a Cassandra cluster based on certain aspects of its configuration.
Key Aspects of Cassandra DataModel
There are three important aspects of Cassandra DataModel and they are
a)Column,SuperColumn
b)Column Family,SuperColumnFamily
c)Keyspace
Column:
Column is a smallest increment of Data.Its a tuple that contains name,value and timestamp.An example column structure represented using JSON-ish format as below
{
name:eventId,
value:1245,
timestamp:123456789
}
Timestamp is default part of every column that you define in Cassandra.The name and value are internally stored as byte[] by cassandra and can be of any length

A SuperColumn is a tuple w/ a binary name & a value which is a map containing an unbounded number of Columns – keyed by the Column‘s name. Keeping with the JSON-ish notation we get:
{ // this is a SuperColumn
name: "homeAddress",
// with an infinite list of Columns
value: {
// note the keys is the name of the Column
street: {name: "street", value: "4444 x street", timestamp: 123456789},
city: {name: "city", value: "san jose", timestamp: 123456789},
zip: {name: "zip", value: "95136", timestamp: 123456789},
}
}

Column Vs SuperColumn
Columns and SuperColumns are both a tuples w/ a name & value. The key difference is that a standard Column‘s value is a “string” and in a SuperColumn the value is a Map of Columns. That’s the main difference their values contain different types of data. Another minor difference is that SuperColumn‘s don’t have a timestamp component to them.
ColumnFamily
A column family is a structure used to group both columns and supercolumns.Column family are of two types a)standard b)supercolumnfamily
A column family can be compared to a table in the RDBMS world.It can be imagined as a table with infinite number of rows.In a column family each row contains a key and a map of columns.Keys in the map are names of columns and values are columns themselves.There are few key aspects to column family in Cassandra
a)Rows do not have a predefined list of columns they can contain
b)There is no specific schema enforced at this level
Example of a ColumnFamily
UserProfile={//this is a ColumnFamily
homeAddress: {// this is the key to this Row inside the C
street:"4444 x street",
city:"san jose",
zip: "95136",
timestamp: 123456789,
}
homeAddressVacation: {// this is the key to this Row inside the C
street:"1111 x street",
city:"san fransisco",
zip: "9500",
phone: "(888) 555-1212" ,
timestamp: 123456789,
}
}
As per the example above you can see that the row with key homeAddress has only street,city,zip and timestamp whereas the row with key homeAddressVacation has street,city,zip,phone and timestamp.The rows in Cassandra can have varying number of columns and this is basically the schemaless aspect of Cassandra
SuperColumnFamily
A column family can be super too.When a ColumnFamily is of type Super we have the opposite: each Row contains a map of SuperColumns. The map is keyed with the name of each SuperColumn and the value is the SuperColumn itself
UserProfile={//this is a ColumnFamily
homeAddress: {// this is the key to this Row inside the SuperColumnFamily
// now we have an infinite # of super columns in this row
// the keys inside the row are the names for the SuperColumns
friend1:{street:"4444 x street", city:"san jose", zip: "95136", timestamp: 123456789}
friend2:{street:"111 x street", city:"san fransisco", zip: "95122", timestamp: 123456789}
}
homeAddressVacation: {// this is the key to this Row inside the SuperColumnFamily
// now we have an infinite # of super columns in this row
// the keys inside the row are the names for the SuperColumns
friendA:{street:"1111 x street",city:"san fransisco", zip: "95000",phone: "(888) 555-1212",timestamp: 123456789}
friendB:{street:"2222 x street",city:"san fransisco", zip: "95010",phone: "(888) 555-1212",timestamp: 123456789}
}
}

Data Types of Columns in Cassandra
Columns are normally sorted by the column type and the column types in cassandra are
a)BytesType
b)UTF8Type
c)AsciiType
d)LongType
e)LexicalUUIDType
f)TimeUUIDType
How data is written in Cassandra
Every time a Cassandra node receives a request to store data it consistently hashes the data, with md5 when using RandomPartitioner, to get a “token” value. The token range for data is 0 – 2^127.
Every node in a Cassandra cluster, or “ring”, is given an initial token. This initial token defines the end of the range a node is responsible for the same.
Cassandra is not “fixed” in the way that it places data around the ring. It uses two components, Snitches and Strategies, to determine which nodes will receive copies of data. Snitches define proximity of nodes within the ring. Strategies use the information Snitches provide them about node proximity along with an implemented algorithm to collect nodes that will receive writes.

Write Process of Cassandra
All the write operations are written to a commit log and from the commit log the data is populated to the memtable (in memmory table) and then eventually pushed to the underlying SSTable

Read Process of Cassandra
During the read the data is first looked up from in memmory Memtable and if the data is not present in the Memtables the data is read from underlying SStable directly

- Basic Read /Query operations of Cassandra
a)get:retreive by column name
b)multiget:retreive by column name for a set of keys
c)get_slice:retreive by column name or range of column_names
d)multiget_slice:a subset of column for a set of keys
e)get_count:number of columns or sub colums
f)get_range_slice:subset of columns for a range of keys
No comments:
Post a Comment